
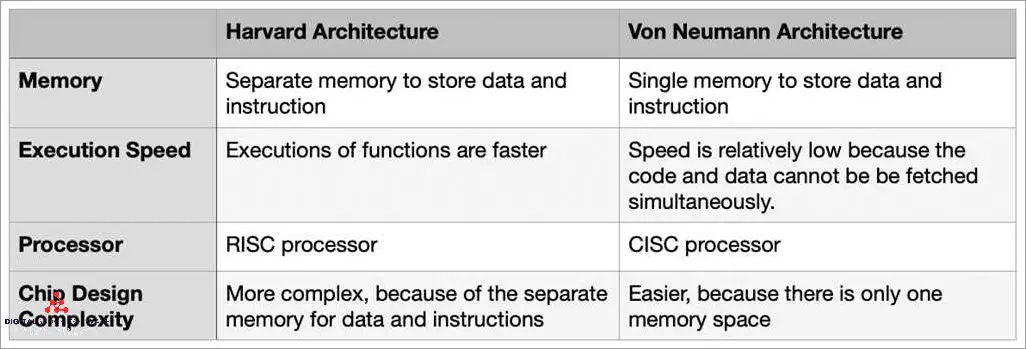
The Harvard and von Neumann architectures are two different approaches to designing computer systems. The main difference lies in the way they handle data and instructions. In the von Neumann architecture, data and instructions are stored in the same memory, while the Harvard architecture uses separate memory for data and instructions.
One of the key advantages of the Harvard architecture is its efficiency. Since the data and instructions are stored in separate memory modules, the processor can simultaneously fetch an instruction and access data, which results in faster processing times. In contrast, the von Neumann architecture needs to fetch an instruction and then fetch the data it operates on sequentially, which can lead to slower performance.
In the Harvard architecture, the separate memories for data and instructions are accessed by separate buses, which allows for better bus utilization and faster data transfer rates. This can improve the overall performance of the system. In the von Neumann architecture, the same bus is used for both data and instructions, which can limit the bus capacity and lead to lower performance.
Pipelining is another area where the Harvard architecture outshines the von Neumann architecture. In pipelining, multiple instructions are executed concurrently in different stages of the processor. The Harvard architecture can exploit this technique more efficiently than the von Neumann architecture, as it can fetch an instruction and access data simultaneously. This can further enhance the performance of the system.
Overall, the Harvard architecture offers better performance and efficiency compared to the von Neumann architecture, thanks to its separate memory modules for data and instructions, improved bus utilization, and better pipelining capabilities. However, it is worth noting that the von Neumann architecture is still widely used in modern computer systems due to its simplicity and lower cost.
Contents
- 1 Overview of Harvard Architecture and von Neumann Architecture
- 2 Comparing Harvard Architecture vs von Neumann
- 3 Memory Organization
- 4 Instruction Execution
- 5 Performance and Efficiency
- 6 Summary of the Differences
- 7 FAQ about topic “Comparing Harvard Architecture vs von Neumann: Understanding the Differences”
- 8 What is the difference between Harvard Architecture and von Neumann?
- 9 Which architecture is better for performance: Harvard or von Neumann?
- 10 Can I upgrade a Harvard Architecture computer to use von Neumann?
- 11 Are there any real-world applications that use Harvard Architecture?
- 12 What are the advantages of von Neumann architecture?
Overview of Harvard Architecture and von Neumann Architecture

The Harvard architecture and von Neumann architecture are two different system architectures used in computer hardware. They have distinct features and structures that impact their performance and efficiency.
The von Neumann architecture, named after the mathematician and computer scientist John von Neumann, is a type of system architecture commonly used in modern processors. It follows a fetch-decode-execute cycle, in which instructions and data are stored in the same memory and accessed sequentially. The processor retrieves instructions from memory, decodes them, and executes them one by one. This architecture allows for flexibility and simplicity in programming, but it can lead to performance bottlenecks due to limited bandwidth for fetching instructions and data.
In contrast, the Harvard architecture separates the instruction and data memory, providing separate hardware for each. This allows for simultaneous access to both instruction and data, improving efficiency and performance. The Harvard architecture also supports pipelining, a technique that enables the processor to execute multiple instructions in parallel, further enhancing performance.
With the von Neumann architecture, both instructions and data are stored in the same memory, which can lead to potential bottlenecks and slower execution times. In the Harvard architecture, on the other hand, instructions and data are stored in separate memories, allowing for faster and more efficient execution.
In summary, the Harvard architecture and von Neumann architecture are two different system architectures used in computer hardware. The Harvard architecture features separate instruction and data memories, enabling faster and more efficient execution. The von Neumann architecture, on the other hand, stores both instructions and data in the same memory, which can lead to potential performance bottlenecks. Understanding the differences between these two architectures can help in optimizing system performance and designing more efficient computer hardware.
What is Harvard Architecture?
Harvard Architecture is a computer system design that separates the fetch and execute operations for instructions and data into separate memory systems. It is named after the Harvard University where the architecture was first implemented.
In the Harvard Architecture, there are separate physical memory systems for storing instructions and data. This separation allows the processor to concurrently fetch an instruction from the instruction memory while retrieving data from the data memory.
One of the key advantages of Harvard Architecture is its efficiency in fetching and executing instructions. Since the instruction memory is separate from the data memory, the processor can access both at the same time, resulting in faster execution times and improved performance.
In addition, Harvard Architecture often includes separate hardware registers for storing data and instructions, further enhancing its efficiency. These registers allow for quick access and manipulation of data, enabling faster execution of instructions.
Harvard Architecture is different from the von Neumann architecture, where instructions and data are stored in the same memory system. In von Neumann architecture, the processor fetches instructions and data from the same memory, which can introduce bottlenecks and decrease performance.
Pipelining is a technique often used in Harvard Architecture to further improve performance. It allows overlapping of fetch, decode, execute, and memory access stages of an instruction, enabling multiple instructions to be executed simultaneously.
Overall, the Harvard Architecture offers improved performance and control over instruction and data access compared to the von Neumann architecture. It is commonly used in embedded systems and microcontrollers where efficiency and performance are essential.
What is von Neumann Architecture?
The von Neumann architecture is a computer system design that is named after the Hungarian-American mathematician and computer scientist John von Neumann. It is a type of architecture that allows a computer to store and execute instructions in a sequential manner.
In the von Neumann architecture, both the instructions and the data are stored in the same memory and are addressed using the same address space. This unified memory allows for the instructions to be fetched from memory and executed by the processor.
One of the key features of the von Neumann architecture is the use of a control unit, which oversees the execution of instructions. The control unit fetches instructions from memory, decodes them, and then executes them. It also synchronizes the activities of the various components of the computer system, ensuring that instructions are executed in the correct sequence.
The von Neumann architecture also includes a set of registers, which are small, high-speed memory locations used to store temporary data during the execution of instructions. These registers can be used to hold data or addresses, and they play a crucial role in the efficiency of the system.
One limitation of the von Neumann architecture is that it can only execute one instruction at a time. However, this limitation can be mitigated by using techniques such as pipelining, which allows multiple instructions to be processed simultaneously. Another limitation is that the von Neumann architecture does not separate the memory and the instruction fetch and execute hardware. This can limit the efficiency of the system in certain cases.
In contrast, the Harvard architecture, which is an alternative to the von Neumann architecture, separates the memory used for storing data and instructions, allowing for the simultaneous fetch and execution of instructions. This can lead to improved performance in certain situations.
Comparing Harvard Architecture vs von Neumann
In the field of computer science, the von Neumann architecture is a system where the execution of instructions and the fetching of data occur in the same memory. On the other hand, the Harvard architecture separates the storage of instructions and data into separate memory systems.
The von Neumann architecture is known for its efficiency and simplicity. In this system, data and instructions are stored together in the same memory, making it easy to fetch them for execution. However, this architecture may face performance issues when it comes to executing simultaneous tasks, as the processor can only fetch one instruction at a time.
In contrast, the Harvard architecture achieves better efficiency by storing data and instructions in separate memory systems. This allows for parallel fetching of instructions and data, improving the overall performance of the system. Additionally, Harvard architecture often includes separate memory for storing registers, which further enhances the performance of the processor.
The von Neumann architecture relies on a control unit that fetches instructions from memory and executes them sequentially. This sequential execution can lead to performance bottlenecks, especially in tasks that require extensive data processing. In contrast, the Harvard architecture supports pipelining, which enables the processor to execute multiple instructions simultaneously, resulting in faster execution speed.
In summary, while the von Neumann architecture offers simplicity and ease of use, the Harvard architecture provides better performance and efficiency through separate memory systems, pipelining, and the use of registers. Choosing between these two architectures depends on the specific requirements of the system and the tasks it needs to perform.
Memory Organization

In the context of comparing Harvard Architecture vs von Neumann, one of the key differences lies in the memory organization. In the von Neumann architecture, the memory is typically organized as a single unified entity that stores both instructions and data. This means that the instructions and data are stored in the same memory space, and the processor needs to fetch them sequentially.
In contrast, the Harvard architecture separates the memory into two distinct entities: one for instructions and one for data. This allows for simultaneous access of instructions and data, as the control and data paths are separate within the processor. The instructions and data can be fetched simultaneously, which can improve the performance and efficiency of the system.
The hardware implementation of the Harvard architecture enables the use of pipelining, where multiple instructions can be simultaneously processed in different stages of the pipeline. This further enhances the performance of the system by overlapping the fetch, decode, and execution stages.
While the von Neumann architecture only uses a single memory space for both instructions and data, the Harvard architecture has separate memories for instructions and data. This separation can lead to improved efficiency since the processor doesn’t have to handle fetch conflicts between instructions and data.
Overall, the memory organization in the Harvard architecture offers advantages in terms of performance and efficiency compared to the von Neumann architecture. However, this comes at the cost of increased hardware complexity due to the need for separate instruction and data memories.
How does Harvard Architecture organize memory?
In Harvard Architecture, the memory is organized in a separate and dedicated way compared to von Neumann architecture. This organization helps in improving the performance and efficiency of the system.
In Harvard Architecture, there are separate physical memories for instructions and data. This means that the instructions and data are stored in separate memory systems, each with its own set of control hardware. This separation allows for simultaneous instruction fetching and data access, which can result in faster and more efficient execution of programs.
The instruction memory consists of a set of registers or cache that store the instructions to be executed by the processor. This allows for quick access to the instructions and enables the processor to fetch the next instruction while executing the current one.
On the other hand, the data memory stores the data that is used and manipulated by the processor during program execution. The data memory may also have its own set of registers or cache for faster data access.
By organizing the memory in this way, Harvard Architecture can achieve higher performance and efficiency compared to von Neumann architecture. The separate instruction and data memories allow for parallel processing, where the processor can simultaneously fetch an instruction while accessing data, resulting in improved overall system speed.
How does von Neumann Architecture organize memory?
In von Neumann Architecture, memory is organized in a hierarchical structure designed for efficiency and optimal data storage. The memory system consists of registers, which are small, high-speed storage locations that hold data and instructions that the processor will execute. These registers are located inside the processor’s hardware.
The memory in von Neumann Architecture is not separate for instructions and data, unlike Harvard Architecture. Instead, instructions and data are both stored in the same memory system. This means that the processor needs to go through a fetch and control cycle in order to retrieve the necessary data and instructions for execution.
The fetch and control cycle involves the processor fetching an instruction from memory, decoding it to determine the necessary operations, and executing those operations. The data needed for execution is also fetched from memory during this cycle. This process allows for a more efficient use of memory resources, as instructions and data can be stored in the same memory modules.
Another important feature of von Neumann Architecture is pipelining. Pipelining allows the processor to fetch, decode, and execute instructions simultaneously, which improves overall performance. By overlapping these stages of instruction execution, the processor can achieve a higher throughput and faster execution time.
In summary, von Neumann Architecture organizes memory by storing both instructions and data in the same memory system. The memory is organized hierarchically, with registers holding the most frequently accessed data and instructions. The fetch and control cycle allows the processor to efficiently retrieve the necessary data and instructions for execution. Pipelining further enhances the efficiency and performance of von Neumann-based systems.
Instruction Execution
In both Harvard and von Neumann architectures, instruction execution is a fundamental process in a computing system. It refers to the way a processor carries out the instructions stored in memory.
In the Harvard architecture system, the instruction execution is performed using a separate instruction and data memory. This design allows the processor to fetch and execute instructions independently from accessing data. The instruction fetch and execution can happen simultaneously, which enhances performance and efficiency.
In contrast, the von Neumann architecture uses a single memory for both instructions and data. The processor fetches the instructions and the corresponding data from the same memory. This design simplifies the memory management but may lead to performance limitations, as the processor cannot fetch and execute instructions simultaneously.
Both architectures may incorporate pipelining, a technique that allows overlapping the execution of multiple instructions. In the Harvard architecture, separate instruction and data memories facilitate efficient pipelining, as the processor can fetch the next instruction while executing the current one. On the other hand, the von Neumann architecture’s single memory may introduce delays in the pipeline due to conflicts between fetching instructions and accessing data.
During instruction execution, both architectures rely on registers to store intermediate results and control signals. These registers hold data and instructions during processing and facilitate the execution of various operations. However, the register usage and organization may vary between the Harvard and von Neumann architectures.
Overall, the difference in instruction execution between the Harvard and von Neumann architectures lies in the memory organization and efficiency. The Harvard architecture’s separate instruction and data memories enable simultaneous fetch and execution, enhancing performance. Meanwhile, the von Neumann architecture’s shared memory simplifies memory management but may limit performance due to conflicts between instructions and data access.
How does Harvard Architecture execute instructions?
In Harvard Architecture, the instructions and data are stored in separate memory systems, which allows for simultaneous data fetch and instruction execution. This separation ensures that data and instructions do not interfere with each other, leading to more efficient execution.
The hardware of a Harvard Architecture system includes separate instruction and data buses, control units, and registers. The instruction fetch unit is responsible for retrieving instructions from the instruction memory, while the data fetch unit fetches data from the data memory.
One key feature of Harvard Architecture is the use of pipelining, which improves performance by allowing multiple instructions to be executed simultaneously. This is achieved by breaking down the instruction execution into smaller stages, such as instruction fetch, decode, execute, and write back.
The control unit plays a crucial role in directing the execution of instructions. It manages the flow of data and ensures that the instructions are executed in the correct order and at the appropriate time.
The separate memory systems in Harvard Architecture enable faster and more efficient processing. The instruction memory can be optimized for sequential access, while the data memory can be optimized for random access, resulting in improved overall system performance.
Harvard Architecture also utilizes registers to store intermediate values and operands during instruction execution. These registers help reduce the need for frequent memory access, which further improves the efficiency of the processor.
In comparison to von Neumann Architecture, Harvard Architecture’s separate instruction and data memory systems provide better performance and efficiency by allowing simultaneous instruction execution and data fetch. This architectural difference is particularly advantageous in applications that require high-speed processing and real-time data handling.
How does von Neumann Architecture execute instructions?
In von Neumann Architecture, instructions are stored in the same memory as data. The processor fetches instructions from memory and executes them one at a time. This architecture is characterized by a single shared bus for both data and instructions.
When the processor wants to execute an instruction, it first fetches the instruction from memory. This is done by sending the memory address of the instruction to the memory module. The memory module then retrieves the instruction and sends it back to the processor.
Once the instruction is fetched, the processor decodes and interprets the instruction. It determines the type of operation to be performed and the operands involved. The control unit of the processor ensures that the instruction is executed correctly by coordinating the execution of different parts of the processor.
The processor then executes the instruction by performing the specified operation on the data. This operation may involve arithmetic calculations, logical operations, or memory accesses. The result of the operation is stored back in memory or in a register.
After the instruction is executed, the processor fetches the next instruction from memory and the process continues. This sequential execution of instructions is the basis of von Neumann Architecture.
Although von Neumann Architecture provides a simple and flexible system, it can suffer from performance limitations. The shared bus for data and instructions can cause bottlenecks and limit the efficiency of data transfer. However, techniques like pipelining and caching can be used to improve the performance of von Neumann Architecture.
Performance and Efficiency

The performance and efficiency of a processor-memory system are crucial factors in determining the overall effectiveness of a computer architecture. In the comparison between Harvard and von Neumann architectures, these aspects play a significant role.
In the von Neumann architecture, both instructions and data are stored together in the same memory system. This design makes it easier to implement and control the system, but it also introduces potential performance limitations. With shared memory, the processor needs to fetch both instructions and data, leading to possible delays and bottlenecks.
On the other hand, the Harvard architecture employs separate memories for instructions and data. This separation allows for simultaneous access, enabling faster execution and improved performance. The processor can fetch instructions and data in parallel, enhancing the overall efficiency of the system.
Furthermore, the Harvard architecture can take advantage of pipelining, a technique where multiple instructions are executed concurrently in different stages of the processor pipeline. This parallelism increases the overall throughput of the system and contributes to improved performance.
Another factor that influences performance and efficiency is the presence of separate instruction and data caches in the Harvard architecture. These caches provide faster access to frequently used instructions and data, reducing the need to access slower main memory. This cache hierarchy helps to minimize the delays caused by memory access, ensuring smoother and faster execution.
In summary, the Harvard architecture offers potential advantages in performance and efficiency compared to the von Neumann architecture. The separation of instruction and data memory, combined with techniques like pipelining and caching, allows for faster and more efficient execution of instructions in the hardware-controlled system.
Advantages of Harvard Architecture
The Harvard architecture offers several advantages over the von Neumann architecture in terms of performance and efficiency.
Separate instruction and data memory: One of the key advantages of the Harvard architecture is that it has separate memories for instructions and data. This allows the processor to simultaneously fetch an instruction from the instruction memory and retrieve data from the data memory. By keeping these two types of memory separate, the Harvard architecture can achieve higher performance compared to the von Neumann architecture.
Faster instruction fetch and data access: Having separate instruction and data memories in the Harvard architecture enables parallel access to both types of memory, resulting in faster instruction fetches and data access. This can significantly improve the overall execution speed of a processor using Harvard architecture.
Efficiency in pipelining: Another advantage of Harvard architecture is its efficiency in pipelining. Pipelining is a technique used in processors to increase their performance by allowing multiple instructions to be executed simultaneously in different stages of the pipeline. In Harvard architecture, the separate instruction and data memories make it easier to implement pipelining, as there is no need to fetch both instruction and data from the same memory.
Dedicated instruction and data registers: Harvard architecture typically employs separate instruction and data registers. These dedicated registers allow faster access to instructions and data, enabling quicker execution of instructions and improved overall system performance. In contrast, von Neumann architecture uses a single set of registers for both instructions and data, which can result in slower execution and lower efficiency.
System stability: The separation of instruction and data memory in Harvard architecture also contributes to system stability. Since they operate independently, a malfunction or error in the data memory will not affect the instruction memory, and vice versa. This isolation ensures the overall system reliability.
In conclusion, the Harvard architecture offers advantages in terms of performance, efficiency, pipelining, dedicated registers, and system stability when compared to the von Neumann architecture. Its separate instruction and data memories, faster access times, and dedicated registers contribute to its superior performance in various computing applications.
Advantages of von Neumann Architecture
The von Neumann architecture, also known as the stored program architecture, offers several advantages over the Harvard architecture:
- Pipelining: The von Neumann architecture allows for pipelining, a technique where multiple instructions are executed simultaneously, improving the overall efficiency of the processor.
- Single memory system: In the von Neumann architecture, the same memory is used for storing both data and instructions. This simplifies the system design and reduces the cost of hardware.
- Control and data in the same memory: Since the control instructions and data are stored in the same memory, it is easier to fetch the necessary instructions and data for execution.
- Flexibility: The von Neumann architecture allows for flexibility in terms of programming, as the same memory can be used for both storing data and instructions.
- Performance: The von Neumann architecture provides good performance for general-purpose computing tasks, as it allows for efficient execution of instructions and easy access to data in memory.
In summary, the von Neumann architecture has the advantage of pipelining, a single memory system for both control instructions and data, flexibility in programming, and good performance for general-purpose computing. These advantages make it a popular choice for most computer systems.
Summary of the Differences

Harvard Architecture and von Neumann Architecture are two different approaches to designing computer systems. Their main differences lie in the way they handle data and instructions, which impact their performance, efficiency, and overall hardware design.
In the Harvard Architecture, the processor has separate control and data pathways. This means that data and instructions are stored in separate memory units and are accessed independently. This allows for simultaneous fetching of both data and instructions, which can improve the overall system performance.
On the other hand, von Neumann Architecture uses a single memory unit to store both data and instructions. This means that data and instructions are fetched sequentially, which can result in a slower overall system performance when compared to Harvard Architecture.
In terms of memory efficiency, Harvard Architecture is generally more efficient. This is because it doesn’t need to allocate memory for the storage of both data and instructions in a single memory unit, as in von Neumann Architecture.
In von Neumann Architecture, the processor needs to fetch instructions one by one, which can cause a bottleneck in the system. In Harvard Architecture, since data and instructions are fetched simultaneously, this bottleneck is reduced, resulting in a more efficient execution of instructions.
Pipelining is a technique that can be used to improve the performance of both Harvard and von Neumann Architectures. It allows for the overlapping execution of multiple instructions. However, Harvard Architecture can benefit more from pipelining due to its separate pathways for data and instructions, allowing for more parallelism.
In summary, Harvard Architecture and von Neumann Architecture differ in terms of how they handle data and instructions, impacting their performance, efficiency, and memory design. Harvard Architecture uses separate pathways for data and instructions, leading to improved performance and efficiency. Von Neumann Architecture uses a single memory unit for both data and instructions, resulting in a potential bottleneck in the system.
Key Takeaways
von Neumann architecture vs Harvard architecture: The key difference between von Neumann and Harvard architectures lies in how the computer handles instructions and data. In von Neumann architecture, instructions and data are stored in the same memory, while in Harvard architecture, they are stored separately.
Performance: The separated memory in Harvard architecture allows for simultaneous fetching of instructions and data, which can improve performance compared to von Neumann architecture, where the processor needs to fetch instructions and data sequentially.
Pipelining: Harvard architecture supports instruction pipelining more efficiently than von Neumann architecture. In a pipelined processor, instructions are divided into stages, and each stage can execute one instruction at a time. The Harvard architecture’s separate instruction and data memory enable concurrent fetching and execution of instructions.
Control: von Neumann architecture uses a single control unit to fetch instructions from memory and execute them sequentially. In Harvard architecture, there are separate control units for instruction and data memory, allowing for parallel operations and potentially increasing efficiency.
Registers: Both von Neumann and Harvard architectures utilize registers to store data temporarily during program execution. However, Harvard architecture typically has separate instruction and data registers, which can further enhance the performance by reducing data access latency.
Efficiency: Due to the separation of instruction and data memory, Harvard architecture offers improved efficiency in terms of simultaneous instruction fetching and data retrieval. This can lead to faster program execution and overall better performance compared to von Neumann architecture.
FAQ about topic “Comparing Harvard Architecture vs von Neumann: Understanding the Differences”
What is the difference between Harvard Architecture and von Neumann?
Harvard Architecture and von Neumann are two different architectures used in computer systems. The main difference is that the Harvard Architecture has separate memory for instructions and data, while von Neumann uses a single memory space for both.
Which architecture is better for performance: Harvard or von Neumann?
Both Harvard and von Neumann architectures have their advantages and disadvantages when it comes to performance. Harvard Architecture typically performs better in terms of speed, as it can fetch instructions and data simultaneously. However, von Neumann architecture is more flexible and can be easily modified, which can be beneficial for certain applications.
Can I upgrade a Harvard Architecture computer to use von Neumann?
No, it is not possible to upgrade a computer with Harvard Architecture to use von Neumann Architecture. The two architectures are fundamentally different and require different hardware designs. If you want to use von Neumann Architecture, you would need to purchase a new computer that is specifically designed for it.
Are there any real-world applications that use Harvard Architecture?
Yes, there are many real-world applications that use Harvard Architecture. One example is microcontrollers, which are used in various electronic devices such as smartphones, washing machines, and cars. Harvard Architecture is also commonly used in digital signal processors (DSPs) for applications such as audio and video processing.
What are the advantages of von Neumann architecture?
Von Neumann architecture has several advantages. One of the main advantages is its flexibility – the ability to store both instructions and data in the same memory space allows for easier and more efficient programming. Von Neumann architecture is also more cost-effective, as it requires less hardware compared to Harvard Architecture. Additionally, von Neumann architecture allows for easier upgrades and modifications to the computer system.

