
When it comes to managing data in a relational database, one of the most important considerations is performance. The efficiency of the database can greatly impact the speed and reliability of queries and other operations. This is where denormalization comes into play.
Denormalization is the process of intentionally introducing redundancy into a database design. This redundancy can help improve query performance by reducing the number of joins required to retrieve the desired data. By storing redundant data in multiple tables, denormalization allows for faster and more efficient retrieval of information.
However, denormalization also brings with it some trade-offs. While it can improve performance, it can also introduce complexity into the database design. Redundant data needs to be carefully managed to ensure data integrity and consistency. Additionally, denormalization can make it more challenging to modify and update data, as changes may need to be propagated across multiple redundant copies of the data.
Despite these challenges, denormalization can be a powerful tool for optimization in SQL databases. By carefully considering the specific requirements of the application and the data relationships, developers can strategically denormalize the schema to maximize performance while maintaining data integrity. This requires a thorough understanding of data modeling, query optimization, and indexing techniques.
In conclusion, denormalization in SQL databases offers significant benefits in terms of performance and efficiency. However, it should be approached with caution and consideration of the potential trade-offs. With careful planning and adherence to best practices, denormalization can help developers achieve optimal database performance without sacrificing data integrity.
Contents
- 1 What is Denormalization?
- 2 Importance of Denormalization in SQL
- 3 Purpose of the Article
- 4 Benefits of Denormalization in SQL
- 5 Increased Query Performance
- 6 Simplified Data Retrieval
- 7 Improved Scalability
- 8 Best Practices for Denormalization in SQL
- 9 Identify Appropriate Tables for Denormalization
- 10 Determine Amount of Denormalization
- 11 Keeping Denormalized Data Consistent
- 12 FAQ about topic “Denormalization in SQL: Understanding the Benefits and Best Practices”
- 13 What is denormalization in SQL?
- 14 What are the benefits of denormalization in SQL?
- 15 Are there any drawbacks of denormalization in SQL?
- 16 When should denormalization be used in SQL?
- 17 What are the best practices for denormalization in SQL?
What is Denormalization?
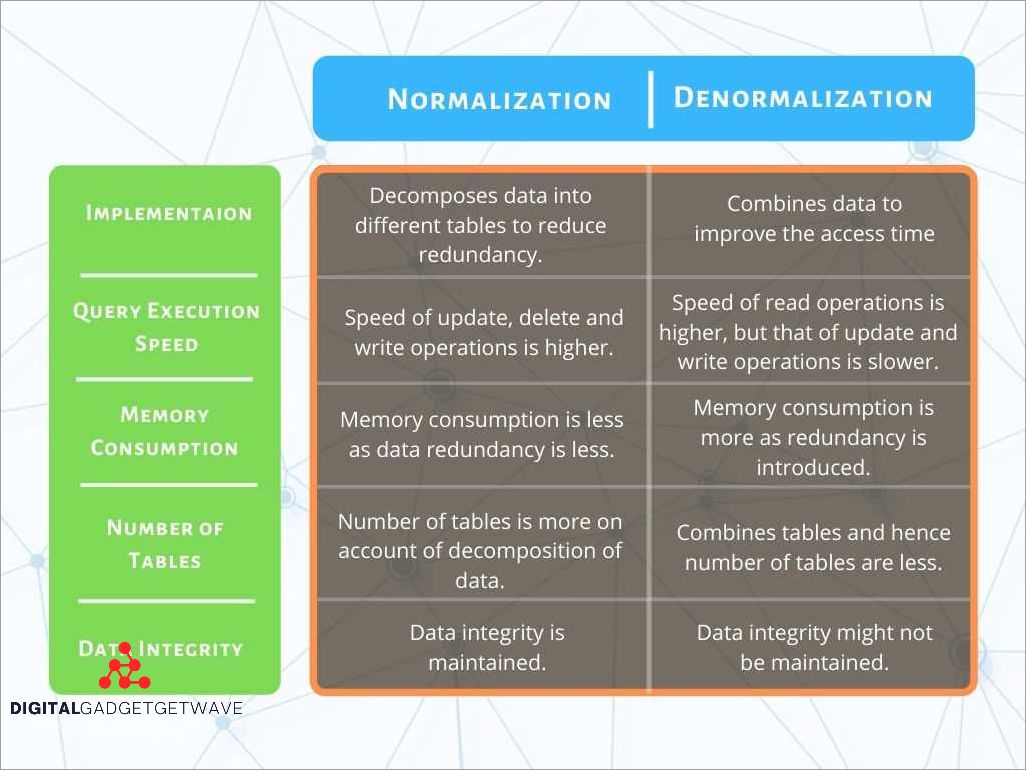
Denormalization in SQL refers to the process of optimizing data modeling in a relational database by reducing or eliminating the use of normalization techniques. Normalization, on the other hand, is a data schema design process that aims to eliminate redundancy and improve data integrity by dividing the data into multiple related tables and establishing relationships between them.
However, normalization can sometimes result in complex join operations and decreased performance efficiency, especially when dealing with large datasets and frequently executed queries. This is where denormalization comes in.
Denormalization involves combining or duplicating data across multiple tables to reduce the need for joining tables and improve query performance. By denormalizing the data schema, redundant data is introduced, but the benefit is faster and more efficient queries that require less processing and fewer joins.
Denormalization can be implemented in different ways, depending on the specific requirements and design of the database. One common approach is to add redundant columns to a table that store data that would otherwise be retrieved through joins. This can greatly simplify and speed up queries that rely on that specific data.
Another denormalization technique involves creating “calculated” columns or summary tables that store precomputed results or aggregated data. This eliminates the need for complex calculations in queries, further enhancing performance.
However, it’s important to note that denormalization should be used judiciously, as it introduces trade-offs between performance and data integrity. Redundant data can lead to data inconsistencies if not properly maintained, and any updates or modifications to denormalized data must be carefully handled to ensure the overall integrity of the database.
In conclusion, denormalization in SQL is a valuable technique for optimizing database performance and query efficiency. By strategically denormalizing the data schema and introducing redundancy, it is possible to significantly improve the speed and efficiency of queries, reducing the need for complex and time-consuming join operations.
Importance of Denormalization in SQL
Denormalization plays a crucial role in the effective management and optimization of data in SQL databases. When designing a database schema and data modeling, normalization is typically used to eliminate redundant data and ensure data integrity. Normalization involves breaking down data into separate tables and creating relationships between them using joins.
While normalization is important for maintaining data integrity and reducing redundancy, it can also lead to performance issues. As the database grows, complex join operations can slow down query execution and impact system efficiency. This is where denormalization comes into play.
Denormalization is the process of reintroducing redundant data into tables to improve query performance and optimize efficiency. By incorporating redundant data, denormalization eliminates the need for multiple table joins, reducing the time required to retrieve data and improving overall system performance.
The efficient use of denormalization in SQL can result in significant performance improvements, especially when dealing with large and complex datasets. It allows for faster data retrieval and reduces the need for expensive join operations. However, it is important to note that denormalization should be used judiciously and in a controlled manner.
While denormalization can improve performance, it can also introduce challenges in terms of data integrity. With redundant data, there is a risk of inconsistencies if not properly managed. It is crucial to ensure that data modifications are carefully handled to maintain data integrity.
In conclusion, denormalization is an essential technique in SQL database design to optimize query performance and enhance system efficiency. By strategically incorporating redundant data, denormalization can greatly improve data retrieval speed and minimize the need for complex join operations. However, it is important to strike a balance between denormalization and normalization to maintain data integrity.
Improving Read Performance

Relational databases are designed to store and manage large amounts of data efficiently. However, as the size of the tables and the complexity of the relationships between them increase, performance can be affected. One way to improve read performance in a database is through denormalization.
Denormalization is the process of adding redundant data to a database in order to improve performance. By duplicating data across tables, the number of joins required to retrieve information can be reduced, resulting in faster query execution.
When denormalizing a database schema, it is important to carefully consider data integrity. Redundancy can introduce potential risks of data inconsistencies, so it is crucial to implement mechanisms to maintain data integrity, such as triggers or stored procedures. The benefits of improved read performance need to be weighed against the potential drawbacks of denormalization.
Data modeling and design play a crucial role in denormalization. By identifying frequently accessed tables and relationships, developers can selectively denormalize specific areas of the database to optimize read performance. This can involve duplicating data or combining multiple tables into a single table.
Efficiency in query execution can also be improved through denormalization. By reducing the need for joins, queries can be executed faster, resulting in improved overall performance. However, it is important to carefully analyze the query patterns and the impact of denormalization on other operations, such as updates and inserts.
In conclusion, denormalization can be a powerful technique for improving read performance in a relational database. By strategically duplicating data and reducing the need for joins, efficient query execution can be achieved. However, care must be taken to ensure data integrity and carefully analyze the impact on other operations. Denormalization should be considered as part of a larger optimization strategy and should be applied selectively based on the specific requirements of the application.
Reducing Data Redundancy
In the realm of database design, denormalization is a technique used to reduce data redundancy within a relational schema. It is the opposite of normalization, which focuses on organizing data into separate tables to maintain data integrity and facilitate efficient querying. Denormalization, on the other hand, allows for the duplication of data across tables to improve performance and simplify complex queries.
By denormalizing a database schema, redundant data is introduced into the design, which can be beneficial in certain scenarios. For example, denormalization can eliminate the need for joining multiple tables in complex queries, resulting in faster query execution times. This can greatly improve the efficiency of the database and enhance the overall performance of applications that rely on it.
Data redundancy can also be reduced through denormalization by storing calculated or aggregated values directly within the table. This eliminates the need for recalculating these values every time a query is executed, leading to significant performance gains. Additionally, denormalization can simplify the data modeling process by allowing for the representation of hierarchical or recursive relationships without the need for additional tables.
However, it is important to note that denormalization should be approached with caution. While it can offer performance benefits, it can also introduce integrity issues if not implemented correctly. Maintaining data integrity becomes more challenging in denormalized schemas, as updates to redundant data may need to be propagated across multiple tables. Therefore, careful consideration should be given to the requirements of the application, the specific use cases, and the potential trade-offs between performance and data integrity.
In conclusion, denormalization plays a crucial role in improving the performance and efficiency of a database system by reducing data redundancy. It allows for faster query execution and simplifies complex data modeling scenarios. However, careful planning and consideration are necessary to avoid compromising data integrity and ensure optimal performance. By striking the right balance between normalization and denormalization, developers can achieve a well-designed and performant database schema.
Enabling Flexibility in Data Retrieval

One of the core benefits of denormalization in SQL is the ability to enable flexibility in data retrieval. Traditionally, relational databases emphasize normalization, which involves breaking data into smaller, related tables to ensure data integrity and optimize storage space. However, this normalized design can sometimes hinder performance and efficiency when it comes to retrieving data.
Denormalization, on the other hand, involves combining data from multiple tables into a single, redundant table. This denormalized schema makes it easier to retrieve data, as it eliminates the need for costly joins and reduces the complexity of queries. By duplicating data and avoiding complex relationships, denormalization can lead to faster and more efficient data retrieval.
When it comes to database design and data modeling choices, denormalization can be a valuable strategy for optimizing data retrieval. By denormalizing specific tables or even entire databases, organizations can tailor their data models to prioritize certain types of queries or reports. This flexibility allows for faster processing and retrieval of specific data, which can be crucial in high-demand environments where quick access to information is a priority.
Furthermore, by utilizing denormalization techniques, data can be indexed more effectively. Indexing plays a crucial role in improving query performance, as it allows the database to quickly locate and retrieve specific data. By denormalizing tables, data can be stored in a way that aligns with the most frequently performed queries, enabling more efficient indexing strategies and speeding up data retrieval even further.
Of course, it’s important to strike a balance between normalization and denormalization when designing a database schema. While denormalization can provide significant benefits in terms of data retrieval efficiency, it may sacrifice some data integrity and storage optimization. It’s essential to carefully analyze the specific requirements and priorities of the system and make informed decisions about denormalization to ensure the overall effectiveness and reliability of the database.
Purpose of the Article
The purpose of this article is to explore the concept of denormalization in SQL database design and understand its benefits and best practices. Denormalization is a technique used to optimize database performance by reducing the number of joins required for a query and improving overall efficiency. By denormalizing a database, redundancy is introduced, but it can greatly enhance data retrieval speed and simplify complex queries.
In a relational database, data is typically organized into separate tables with relationships between them. This normalized approach ensures data integrity and reduces redundancy, but it can also lead to slower performance, especially when complex queries involving multiple tables and joins are executed. Denormalization, on the other hand, involves duplicating data to eliminate or reduce the need for joins, thereby optimizing the query execution time.
This article will discuss the different ways in which denormalization can be applied, such as through the use of redundant data, precalculation of values, and storing derived data. It will also explore the trade-offs involved in denormalization, such as potential data integrity issues and increased storage requirements. By understanding these trade-offs, database designers can make informed decisions about when and how to denormalize their schemas.
Furthermore, this article will provide best practices for denormalization, such as carefully considering the specific requirements of the database and application, monitoring and refining the denormalized schema to maintain data integrity, and properly indexing the denormalized tables to enhance query performance. It will also discuss the importance of data modeling and how a well-designed schema can contribute to the effectiveness of denormalization.
Overall, this article aims to equip readers with a comprehensive understanding of denormalization in SQL and its role in optimizing database performance. By implementing denormalization techniques correctly and following best practices, developers and database administrators can achieve significant improvements in query speed and overall efficiency.
Benefits of Denormalization in SQL
Normalization is a fundamental concept in relational database design, aimed at reducing redundancy and improving data integrity. However, there are situations where denormalization can provide significant benefits, especially when it comes to performance optimization.
One key benefit of denormalization is improved query performance. In a highly normalized schema, accessing data often requires performing complex joins between multiple tables. This can be time-consuming, especially for large datasets. By denormalizing the data and storing redundant information in a single table, joins can be eliminated or minimized, resulting in faster query execution.
Another advantage of denormalization is the simplification of relationships. In a normalized schema, the relationships between tables can become complex and difficult to manage. Denormalization can help in simplifying these relationships by reducing the number of tables involved and making the database schema easier to understand and maintain.
Furthermore, denormalization can enhance data modeling flexibility. In a normalized schema, making changes to the schema can be challenging, as adding or modifying tables and relationships can impact other parts of the database. By denormalizing the data, the schema becomes more flexible, allowing for easier modifications and adaptations to the evolving needs of the system.
Lastly, denormalization can lead to improved indexing and data retrieval efficiency. In a normalized schema, multiple table indexes may be required to optimize various queries. By denormalizing the data and consolidating it into a single table, indexes can be created and optimized more effectively, resulting in faster data retrieval.
While denormalization offers these benefits, it is important to note that it should be used judiciously. Excessive denormalization can lead to data redundancy, potential inconsistencies, and increased complexity. Therefore, careful consideration should be given to the specific requirements of the system and the optimal balance between normalization and denormalization.
Increased Query Performance
One of the key benefits of denormalization in SQL is increased query performance. When data is normalized, it is typically spread across multiple tables. This requires the use of joins to retrieve the necessary information from different tables. While normalization ensures data integrity and makes data modeling easier, it can result in slower performance due to the need for frequent joins.
Denormalization, on the other hand, involves combining related data into a single table or duplicating data across multiple tables. This eliminates the need for joins, as all the required data can be retrieved from a single table. As a result, queries can be executed more efficiently and with lower overhead, leading to improved performance.
In addition to reducing the need for joins and improving query performance, denormalization also allows for better indexing and optimization. With denormalized tables, it becomes easier to create indexes that can further enhance the efficiency of query execution.
Furthermore, denormalization can be particularly beneficial in cases where there are complex relationships between tables. By denormalizing the data and merging related entities into a single table, it becomes simpler to navigate and retrieve information. This can significantly improve the speed and efficiency of queries that involve multiple levels of relationships.
Overall, denormalization in SQL can lead to increased query performance by eliminating the need for joins, allowing for better indexing and optimization, and simplifying complex relationships within a database schema. However, it’s important to carefully consider the trade-offs and ensure that denormalization is applied judiciously to maintain data integrity while improving the performance of the system.
Simplified Data Retrieval
Efficient data retrieval is a critical aspect of database design and optimization. Denormalization plays a crucial role in simplifying the process of retrieving data from a relational database.
By denormalizing the database schema, relationships between tables are reduced, leading to improved query performance. In a normalized database, complex joins are often required to retrieve data from multiple tables. However, denormalization eliminates the need for these joins, simplifying the query process.
Denormalization also helps improve efficiency by reducing the number of operations needed to retrieve data. In a normalized database, excessive indexing may be required to maintain data integrity. However, denormalization reduces the need for excessive indexing, resulting in faster query processing.
Data redundancy is a common consequence of denormalization, as redundant data is introduced to simplify data retrieval. While redundancy can have negative consequences for data integrity, it can greatly enhance query performance, especially in read-heavy applications.
When denormalizing the database, it is important to carefully consider the trade-offs between performance and data integrity. Data modeling plays a crucial role in ensuring that the denormalized schema is well-designed and maintains the required level of data integrity.
Overall, denormalization is an effective technique for simplifying data retrieval in SQL. By reducing relationships, improving indexing, and introducing redundancy, query performance can be greatly enhanced. However, careful consideration must be given to the design of the denormalized schema to ensure data integrity is not compromised.
Improved Scalability
Denormalization in SQL can greatly improve scalability in a database system. By reducing the number of joins required to retrieve data, denormalization can help optimize query performance and improve overall efficiency. This is especially important in large-scale databases with complex data models and numerous relationships between tables.
By eliminating data redundancy and incorporating relevant data into a single table, denormalization allows for faster data retrieval and processing. This can result in significant performance improvements, especially for complex queries that involve multiple joins across several tables.
Denormalized schemas also help in improving indexing efficiency. By eliminating the need for joins, denormalization reduces the number of indexes that need to be maintained, resulting in faster query execution times. This can greatly contribute to improved scalability as the database grows in size and complexity.
In addition, denormalization can enhance the overall data integrity of a database system. While traditional normalized schemas enforce strict data constraints and dependencies, denormalization can help achieve a balance between data integrity and performance. By carefully denormalizing specific tables or attributes, database designers can optimize data access and retrieval without sacrificing the integrity of the data.
Overall, denormalization in SQL offers a powerful approach to improving scalability, performance, and efficiency in relational databases. By streamlining data access, reducing redundancy, and optimizing query execution, denormalization can help meet the demands of increasingly complex data models and growing user bases.
Best Practices for Denormalization in SQL
Denormalization in SQL refers to the process of intentionally introducing redundancy in a database design to improve performance and efficiency. While normalization is the standard practice of removing redundancy in data modeling, denormalization is used when there is a need to optimize query performance.
One of the best practices for denormalization is to carefully analyze the database design and identify the specific tables and relationships that can benefit from denormalization. This requires a thorough understanding of the data and its usage patterns.
It is important to strike a balance between redundancy and data integrity when implementing denormalization. Redundancy can help improve query performance, but it can also lead to inconsistencies if not managed properly. Therefore, it is crucial to ensure that data integrity is maintained through appropriate validation and constraints.
Efficiency is a key consideration when denormalizing tables in SQL. This can be achieved by carefully choosing the columns to duplicate or store redundantly. It is important to prioritize columns that are frequently used in queries and joins, as well as those that involve computationally expensive operations.
Indexing plays a crucial role in optimizing performance when working with denormalized tables. By creating appropriate indexes on key columns, the database can quickly locate and retrieve the required data. This helps reduce the cost of joins and improves query execution time.
Another best practice is to thoroughly test and benchmark the performance of the denormalized schema. This involves running various queries and workload simulations to ensure that the denormalization strategy is indeed improving performance. It also helps identify any potential issues or bottlenecks that may arise.
In conclusion, denormalization in SQL can be a powerful technique for improving query performance and efficiency. However, it requires careful planning, analysis, and consideration of various factors such as data integrity, query patterns, and indexing. By following best practices and continuously monitoring and optimizing the denormalized schema, it is possible to achieve significant performance gains in relational databases.
Identify Appropriate Tables for Denormalization
When considering denormalization in SQL, it is important to identify the appropriate tables for this process. Denormalization involves combining or duplicating data in tables to improve query performance and overall efficiency in a database. However, denormalization must be done carefully to maintain data integrity and adhere to good design practices.
The first step in identifying tables for denormalization is to analyze the relationships between the tables in the database schema. Tables that have frequent joins or complex relationships with other tables may benefit from denormalization. By denormalizing these tables and reducing the need for joins, query performance can be significantly improved.
Data modeling techniques can also guide the identification of tables for denormalization. Tables that contain data that is frequently accessed together or queried together can be good candidates for denormalization. By combining related data into a single table, the number of queries and the complexity of joins can be reduced, leading to optimization benefits.
Normalization principles play a role in identifying tables for denormalization as well. Tables that have been normalized to a high degree may benefit from denormalization as a means to optimize certain queries. While normalization is crucial for database integrity, denormalization can provide efficiency gains in specific scenarios.
Another aspect to consider is the presence of redundant data in tables. If there are certain columns or data elements that are duplicated across multiple tables, denormalization can be implemented to eliminate this redundancy. By consolidating redundant data into a single table, storage space can be saved, and query performance can be improved.
Lastly, indexing should be taken into account when identifying tables for denormalization. Tables that have large amounts of data and are frequently queried can benefit from denormalization, as indexing can be more effective on denormalized tables. By reducing the number of joins and increasing the locality of data, denormalization can enhance the efficiency of indexing operations.
Determine Amount of Denormalization
When denormalizing a database, it is important to determine the appropriate amount of denormalization to apply. This involves considering the trade-off between data integrity and query performance.
Indexing is a fundamental aspect of database design and plays a crucial role in optimizing query performance. Normalization helps in reducing redundancy and maintaining data integrity by splitting data into multiple tables and establishing relationships between them. However, excessive normalization can result in complicated joins and slower query performance.
By denormalizing the schema and combining related tables, certain queries can be optimized, leading to improved efficiency. However, it is essential to strike a balance between denormalization and maintaining data integrity. Denormalizing too much can introduce redundancy and increase the risk of data inconsistency.
Data modeling is key to determine the amount of denormalization needed. Understanding the usage patterns and specific requirements of the database can help identify tables and relationships that can be denormalized without compromising data integrity. It is important to analyze the queries frequently executed on the database and identify the areas where denormalization can provide significant performance improvements.
By carefully analyzing the database design and considering the performance impact of joins, you can determine the appropriate amount of denormalization. Optimal denormalization can result in faster query performance, minimize the need for complex joins, and improve overall database efficiency.
Partial Denormalization
Partial denormalization is a technique used in data modeling and database design where some of the tables in a relational database schema are intentionally denormalized to improve query performance and optimization. It is a balance between the normalization principles of reducing data redundancy and maintaining data integrity, and the need for efficient and fast query execution.
By denormalizing specific tables, joins between these tables can be eliminated or reduced, resulting in improved performance. This is especially beneficial in cases where the data being queried is accessed frequently or involves complex relationships. By duplicating data across these tables, queries that require joins can be avoided, leading to faster execution times.
This denormalization technique, however, should be used judiciously. It is important to carefully consider the trade-offs between the benefits of improved query performance and the potential drawbacks of data redundancy and reduced data integrity. Data redundancy can introduce the risk of inconsistency or inaccuracy if not properly managed.
In order to implement partial denormalization effectively, proper indexing plays a critical role. Indexing the denormalized tables appropriately can further enhance the query performance and efficiency. By creating indexes on frequently queried columns, the database engine can quickly retrieve the required data without performing expensive operations such as table scans.
Partial denormalization is particularly useful in scenarios where read operations outnumber write operations. By optimizing the database for read-heavy workloads, the overall system performance can be significantly improved.
It is important to note that partial denormalization is not a one-size-fits-all solution. The choice to denormalize tables should be made based on careful analysis of the specific requirements and characteristics of the data and the expected usage patterns. Additionally, proper monitoring and maintenance of the denormalized schema are necessary to ensure data consistency and integrity.
Full Denormalization
Full denormalization is a database design approach where all the normalized relationships and dependencies between the tables are eliminated, resulting in a single highly redundant and denormalized table. This means that the data is duplicated and stored multiple times across the table, leading to increased redundancy and potential data integrity issues.
While full denormalization goes against the principles of normalization, it can offer several benefits in terms of performance and query optimization. By eliminating the need for joins between tables, full denormalization can greatly improve query performance, as the data is already available in a single table.
However, full denormalization should be used with caution, as it can have a negative impact on data integrity and maintenance. Without the structure provided by normalization, maintaining the consistency and accuracy of data becomes more challenging. Changes to the data in one place may not be reflected in other copies of the data, leading to data inconsistencies.
Indexing plays a crucial role in fully denormalized schemas to optimize query performance. By creating appropriate indexes on denormalized tables, the database can efficiently retrieve the required data without the need for complex join operations. This can greatly improve the overall performance of the database.
It is also important to note that full denormalization may not be suitable for all types of data and scenarios. It is often used in situations where read performance is critical, and the data modeling and schema design can be optimized accordingly. However, it may not be the best approach for systems where data updates and integrity are of utmost importance.
In conclusion, full denormalization can provide performance benefits by eliminating the need for joins and optimizing queries. However, it also introduces redundancy and potential data integrity issues. It should be carefully considered and applied in appropriate scenarios to achieve the desired performance improvements without compromising data integrity.
Keeping Denormalized Data Consistent
One of the main challenges of denormalizing data in a relational database is maintaining data integrity. Denormalization involves duplicating data across multiple tables to improve efficiency and eliminate the need for complex joins. However, this duplication can lead to data inconsistencies if not carefully managed.
To ensure data consistency, it is important to establish processes and rules for updating and maintaining denormalized data. This includes defining how data should be updated, identifying the primary source of truth, and implementing mechanisms to propagate changes to all denormalized copies.
One approach to maintaining data consistency is through the use of database triggers. Triggers can be defined to automatically update denormalized data whenever changes are made to the original source. These triggers can be configured to execute complex logic to ensure that the denormalized data remains synchronized with the normalized tables.
An alternative approach is to use stored procedures or custom application logic to handle the updating of denormalized data. This allows for more control and flexibility in managing the denormalized copies, but it also requires careful implementation to ensure that all updates are properly handled.
Another important consideration for maintaining data consistency is the use of proper indexing and query optimization. Denormalization can lead to increased redundancy, as the same data is stored in multiple tables. To mitigate this, it is important to carefully design indexes and optimize queries to ensure efficient access to the denormalized data.
In conclusion, maintaining data consistency in denormalized schemas is crucial for data integrity and performance. By establishing clear rules, implementing triggers or custom logic, and optimizing queries and indexes, it is possible to keep denormalized data consistent and achieve the desired efficiency improvements in data modeling and relational database design.
FAQ about topic “Denormalization in SQL: Understanding the Benefits and Best Practices”
What is denormalization in SQL?
Denormalization in SQL is a technique used to optimize database performance by reducing the number of joins required in query execution. It involves duplicating data or adding redundant data into tables to eliminate the need for joins between related tables.
What are the benefits of denormalization in SQL?
Denormalization in SQL offers several benefits, including improved query performance, simplified query logic, and reduced overhead of join operations. By eliminating the need for joins, denormalization can significantly speed up complex queries and reduce the load on the database server.
Are there any drawbacks of denormalization in SQL?
While denormalization can bring performance benefits, it also has potential drawbacks. One drawback is increased data redundancy, which can lead to data inconsistencies if not properly managed. Another drawback is increased storage requirements, as denormalization often involves duplicating data. Additionally, denormalization can make data updates more complex and may result in slower write operations.
When should denormalization be used in SQL?
Denormalization should be used in SQL when there is a performance bottleneck caused by frequent joins and complex queries. It is particularly useful in read-heavy applications or for reporting purposes, where quick and efficient retrieval of data is essential. However, denormalization should be carefully implemented and balanced with proper data modeling techniques to avoid potential pitfalls.
What are the best practices for denormalization in SQL?
When denormalizing in SQL, it is important to follow several best practices. Firstly, analyze the query patterns to understand the most common and expensive queries that can benefit from denormalization. Secondly, identify the relationships between tables and determine which ones can be denormalized without introducing data integrity issues. Additionally, implement proper indexing strategies to optimize performance, and monitor and tune the denormalized database over time to ensure continued efficiency.

