
Text matching is a fundamental task in data analysis and natural language processing. It involves finding patterns or substrings within a given string, and it is essential for tasks such as data cleansing, information retrieval, and text mining. However, traditional pattern matching techniques, like regular expressions, may not always be suitable for cases where approximate or fuzzy matching is required. This is where fuzzy matching, which allows for approximate comparison, comes into play.
Fuzzy matching is a technique that enables the comparison of strings based on their similarity rather than strict equality. It takes into account the distance between two strings, which can be measured using various algorithms such as the edit distance. By considering the similarity between strings, fuzzy matching algorithms can handle cases where there are minor differences or inconsistencies in the text, making it ideal for tasks such as spell checking, record linkage, and duplicate detection.
In R, there are several packages and functions available for fuzzy matching. One popular package is the stringdist package, which provides a range of functions for measuring string distances and performing approximate string matching. Another widely used package is the fuzzyjoin package, which extends the dplyr package to perform fuzzy joins on data frames.
When it comes to fuzzy matching in R, it is important to understand the trade-offs between efficiency and accuracy. Some algorithms may be more computationally expensive but offer higher precision, while others may be faster but less accurate. It is crucial to choose the appropriate algorithm and adjust the matching parameters based on the specific requirements of the task at hand.
In this guide, we will explore various fuzzy matching techniques in R, including the use of string distances, regular expressions, and approximate string matching algorithms. We will provide examples and practical tips to efficiently perform fuzzy matching on text data in R, allowing you to enhance your data analysis and text mining workflows.
Contents
What is Fuzzy Match?
Fuzzy match is an algorithm used in the R programming language to perform approximate pattern matching between character strings. It is a technique that allows for the comparison and search of similarity between text strings, even if they are not an exact match.
When using fuzzy match, the algorithm calculates the similarity or distance between two strings by comparing their individual characters, substrings, or sequences. It takes into account factors such as the number of edits or changes needed to transform one string into another, and the presence of patterns or regular expressions within the text.
Fuzzy match is particularly useful in scenarios where exact string matching is not possible or practical, such as when working with noisy or unstructured text data. It enables researchers and data analysts to identify and extract relevant information from text by allowing for approximate matching and pattern recognition.
By using fuzzy match in R, it becomes much easier to find and compare text strings that are similar or closely related, even if they are not an exact match. This can be beneficial in a variety of applications, including data cleaning and preprocessing, natural language processing, text mining, and information retrieval.
In summary, fuzzy match is an efficient text matching technique in R that allows for approximate pattern matching, comparison, and search between text strings. It enhances the capabilities of traditional exact matching by considering factors such as string similarity, edit distance, and the presence of regular expressions. By using fuzzy match, researchers and data analysts can extract meaningful information from text data more effectively.
Importance of Fuzzy Match
The importance of fuzzy match arises from the need to find similarity or distance between strings in a text search. In regular pattern matching, the goal is to find an exact sequence or substring match, but in fuzzy matching, the aim is to find approximate matches.
In R, fuzzy matching is commonly used to compare and match strings based on their similarity. It is particularly useful when dealing with messy or unstructured data, where exact matches may not be possible or practical. Fuzzy match enables the comparison of strings based on their characters, allowing for variations and deviations in the pattern.
Fuzzy match algorithms in R calculate the similarity or distance between strings using methods such as edit distance. Edit distance calculates the minimum number of edits (insertions, deletions, or substitutions) required to transform one string into another. This measure of difference is used to determine the degree of similarity or dissimilarity between two strings.
By performing fuzzy matching, one can identify and find patterns in the text data that are not easily detectable using exact pattern-matching techniques. It enables the identification and grouping of similar strings, even when they are not identical. Fuzzy match allows for a more flexible and inclusive approach to text matching, accommodating for variations and uncertainties that often exist in real-world data.
In summary, fuzzy matching plays a crucial role in text analysis and data manipulation tasks in R. It allows for the comparison of strings based on approximate similarity, enabling the identification of patterns and matches that would otherwise be missed. With fuzzy match, one can handle messy or unstructured data efficiently, enabling more accurate and comprehensive analysis of text data.
Enhancing Data Cleaning and Data Validation
When working with data, it is important to ensure that it is accurate and reliable. Data cleaning and data validation play a crucial role in achieving this goal. One common challenge in data cleaning is dealing with discrepancies and inconsistencies in character strings. Fortunately, there are various techniques and algorithms available in R that can enhance this process.
Regular expressions are powerful tools for searching and manipulating strings. They allow us to define patterns and match strings that follow a specific sequence or structure. By using regular expressions, we can perform advanced pattern-matching operations to identify and correct errors in the data.
Fuzzy matching is another technique that can be used for data cleaning and validation. It involves finding strings that are similar to a given pattern or sequence. The fuzzy matching algorithm calculates the distance or similarity between two strings and determines their level of similarity. This can be useful for identifying potential duplicates or inconsistencies in the data.
edit distance is a popular metric used in fuzzy matching. It measures the number of single-character edits (insertions, deletions, substitutions) required to transform one string into another. By comparing the edit distances between strings, we can identify similar or closely related strings.
In R, there are several packages available that provide functions for fuzzy matching and string comparison. These packages include stringdist, stringdistmatrix, and stringdistvector. They offer efficient algorithms for calculating edit distances, performing fuzzy matching, and comparing strings.
Overall, enhancing data cleaning and data validation with fuzzy matching and pattern-matching algorithms in R can significantly improve the accuracy and reliability of the data. By utilizing these techniques, we can identify inconsistencies, correct errors, and ensure that the data is suitable for analysis and decision-making.
Improving Data Integration and Deduplication
Data integration and deduplication are crucial processes in data management, especially when dealing with large datasets. Matching and identifying duplicate records accurately is essential for maintaining data accuracy and preventing redundancy.
Text matching is a commonly used technique for identifying similarities between strings or text data. It involves comparing the similarity or difference between two or more strings and finding approximate matches based on a given pattern or sequence.
One popular approach to text matching is the fuzzy match algorithm, which allows for approximate matching by considering variations, spelling mistakes, or missing characters in the strings being compared. This algorithm uses techniques such as the Levenshtein distance or the Hamming distance to calculate the similarity between strings.
In addition to fuzzy matching, regular expressions are another useful tool for pattern matching and string comparison. Regular expressions provide a powerful and flexible way to search for specific patterns or substrings within a larger string. By specifying a pattern and using regular expression functions, data integration and deduplication tasks can be significantly improved.
By utilizing fuzzy matching algorithms and regular expressions, organizations can improve their data integration and deduplication processes. These techniques enable accurate identification of similar records, even when there are variations in the data. With enhanced similarity and pattern-matching capabilities, businesses can ensure data quality, remove duplicates, and streamline their data management workflows.
Methods for Fuzzy Match in R
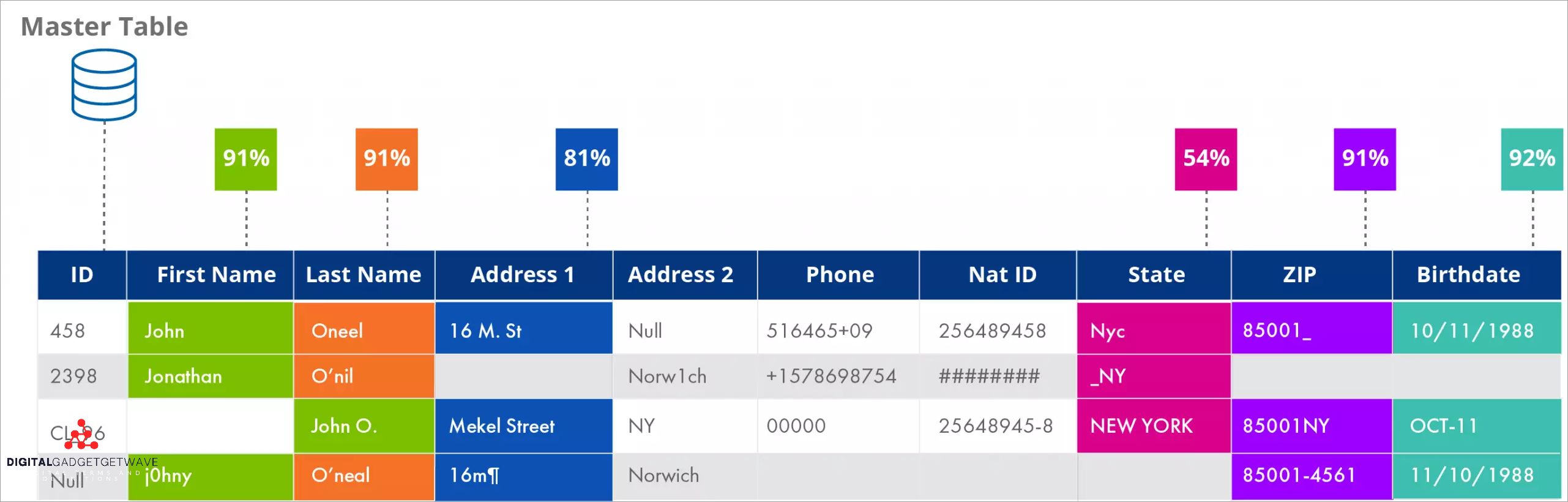
In R, there are several methods available for fuzzy matching, which is the process of finding approximate matches in text based on a given pattern. These methods allow for efficient and accurate matching of patterns in strings, even when there are minor variations or differences in spelling or formatting.
One commonly used method is regular expression matching, which involves specifying a pattern that describes the desired characters or character sequences to match. Regular expression matching is flexible and powerful, allowing for complex pattern-matching operations. It enables the search for approximate matches by using special characters that represent approximate or fuzzy matching, such as the dot (.) to match any character, or the question mark (?) to indicate optional characters.
Another method for fuzzy matching in R is the use of edit distance algorithms. These algorithms measure the similarity or distance between two strings by calculating the minimum number of edit operations (such as insertions, deletions, or substitutions) required to transform one string into the other. By comparing the edit distance between a pattern string and a target string, fuzzy matching can be performed to find approximate matches.
Character-based fuzzy matching is another approach in R, which involves comparing individual characters in two strings to find approximate matches. This method is useful for detecting similarities at the character level, such as finding matches based on common prefixes or suffixes. It can also be used to match substrings within larger strings, allowing for more flexible pattern-matching operations.
Overall, these methods for fuzzy match in R provide powerful tools for efficient and accurate text matching. Whether using regular expressions, edit distance algorithms, or character-based matching, R offers a variety of approaches to perform fuzzy matching and discover approximate matches in text data. These methods can be applied in various contexts, such as data cleaning, record linkage, or text analysis, to enhance the accuracy and effectiveness of pattern-matching operations.
Levenshtein Distance Algorithm
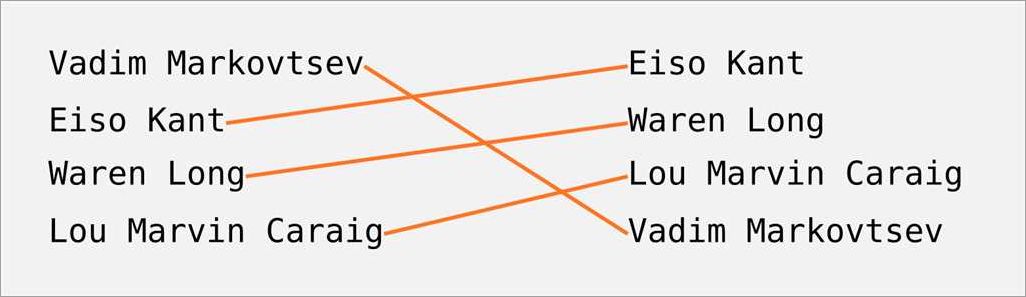
The Levenshtein Distance Algorithm, also known as the edit distance algorithm, is a commonly used method in text matching and pattern-matching tasks. It is an approximate string matching algorithm that measures the difference between two strings.
The algorithm calculates the minimum number of edits (insertions, deletions, and substitutions) required to transform one string into another. These edits are based on individual character comparisons and can be used to determine the similarity between two strings.
In R, the Levenshtein Distance algorithm is implemented in the ‘stringdist’ package, providing a fast and efficient solution for fuzzy matching. This package offers various functions for approximate string matching, including ‘stringdist’, ‘stringdistmatrix’, and ‘amatch’.
With the Levenshtein Distance algorithm, you can easily perform fuzzy searches and find approximate matches for a given pattern within a text or substring. This is particularly useful when dealing with large datasets or when the exact pattern or string is unknown or contains errors.
When using the Levenshtein Distance algorithm for pattern-matching tasks, it’s important to note that it is not limited to just character string comparisons. You can use it for matching regular expressions, comparing numeric values, or even more complex data structures within R.
The result of the Levenshtein Distance algorithm is a numerical value known as the Levenshtein distance, which indicates the minimum number of edits required to transform one string into another. This distance can be used as a measure of similarity or as a criterion for approximate string matching.
Soundex Algorithm
The Soundex algorithm is a phonetic algorithm used for fuzzy matching in text processing. It was designed to simplify the matching of names that have different spellings but sound similar when pronounced. The algorithm converts a string of characters into a code that represents its pronunciation, allowing for sound-based comparisons rather than direct character comparisons.
The algorithm works by assigning a code to each character in the input string and then grouping similar-sounding characters together. This code is then used to compare strings for similarity. The resulting codes are typically made up of a letter followed by three numbers.
To use the Soundex algorithm in R, you can use the Soundex package, which provides functions for converting strings to their Soundex codes and performing fuzzy matching based on these codes. The main function in the package is the soundex() function, which takes a character vector as input and returns the Soundex codes for each element.
Once you have converted your strings to their Soundex codes, you can compare them using the regular string comparison operators in R. The Soundex codes provide a measure of similarity between strings, and you can use this measure to determine how closely two strings match.
The Soundex algorithm is an approximate string matching algorithm, which means it can be useful for finding patterns or matches in text when the exact spelling is not known. It is particularly useful for matching names or other strings that may have variations in spelling but sound similar when pronounced. It can also be used in combination with other fuzzy matching algorithms, such as edit distance or sequence alignment, to improve the accuracy of the matching process.
In conclusion, the Soundex algorithm provides a way to perform fuzzy matching based on the pronunciation of strings rather than their exact spelling. It can be a powerful tool for finding approximate matches in text data and is often used in applications that require pattern-matching or similarity comparison.
Jaro-Winkler Distance Algorithm
The Jaro-Winkler distance algorithm is a fuzzy matching algorithm used for approximate string comparison. It measures the similarity between two character sequences or strings by comparing their characters and the order in which they appear. This algorithm is particularly useful in text matching and pattern-matching tasks where the exact match is not required, but a fuzzy match is desired.
The Jaro-Winkler distance algorithm works by comparing each character in one string to the characters in the other string, calculating a similarity score based on the number of matching characters and the number of characters in common. The algorithm also takes into account the order of the characters and assigns higher scores to strings that have matching characters in the same positions.
One of the key features of the Jaro-Winkler distance algorithm is its ability to handle substring matching. It not only compares the entire sequences of characters, but also looks for matching substrings within the strings. This makes it suitable for tasks such as fuzzy text search and approximate pattern matching. The algorithm can be used to find approximate matches of a given regular expression or pattern within a larger text.
The Jaro-Winkler distance algorithm computes a numerical value called the Jaro-Winkler distance, which represents the approximate distance between two strings. A lower distance value indicates a higher similarity between the strings. This distance value can be used to rank and compare different strings based on their similarity.
In summary, the Jaro-Winkler distance algorithm is an efficient and reliable method for approximate string comparison and fuzzy matching. It takes into account the characters, order, and substrings present in the strings, allowing for accurate and flexible matching. Whether it is used for matching text, searching for patterns, or evaluating string similarity, the Jaro-Winkler distance algorithm is a valuable tool in the field of natural language processing and data analysis.
Performance Tips for Efficient Text Matching
When performing fuzzy or approximate pattern matching on a large set of strings, it is important to consider the performance of the matching algorithm. Here are some tips to improve the efficiency of text matching in R:
- Choose the right distance or similarity metric: Different fuzzy matching algorithms use different distance or similarity metrics to compare strings. Some commonly used metrics include Levenshtein distance, Jaccard similarity, or cosine similarity. Depending on the specific requirements of the matching task, selecting the appropriate metric can have a significant impact on performance.
- Preprocess the strings: Preprocessing the strings before matching can help improve speed. This can include converting all strings to lowercase, removing unnecessary characters or punctuation, and standardizing formats. By doing so, you reduce the complexity of the matching task and improve the overall efficiency.
- Use substring search instead of full string matching: If you are only interested in finding approximate matches within a larger string, consider using substring search instead of full string matching. This can significantly reduce the number of comparisons needed and improve performance.
- Optimize regular expressions: If using regular expressions for pattern matching, try to optimize them for efficiency. This can include using more specific matching patterns, avoiding unnecessary backtracking, and reducing the complexity of the expression overall.
- Consider implementing indexing or caching: For large datasets, implementing indexing or caching techniques can help improve performance. This involves preprocessing the data and creating data structures, such as data frames or hash tables, that allow for faster searching and matching.
- Parallelize the matching process: If performance is still an issue, consider parallelizing the matching process. This involves breaking down the matching task into smaller subtasks and distributing them across multiple processors or cores. This can significantly speed up the matching process, especially for large datasets.
By following these performance tips, you can improve the efficiency of fuzzy text matching in R, allowing for faster and more accurate pattern matching in your applications.
Using Appropriate Data Structures

In the context of fuzzy matching in R, it is crucial to choose appropriate data structures that can efficiently handle approximate string searches. Traditional data structures like arrays or lists may not be efficient for such tasks, as they lack the necessary algorithms and functions to compare strings and find matches based on similarity.
One commonly used data structure for fuzzy matching in R is the trie, which is a tree-like data structure specifically designed for efficient string search and pattern matching. The trie data structure allows for fast retrieval and comparison of strings based on their prefixes and substrings, making it an ideal choice for approximate string matching.
Another important data structure for fuzzy matching in R is the edit distance matrix. This matrix represents the minimum number of edit operations (such as insertions, deletions, and substitutions) required to transform one string into another. By calculating the edit distance between two strings, we can determine their similarity and make fuzzy matches based on a predefined threshold.
Furthermore, utilizing regular expressions and pattern-matching algorithms can greatly enhance the efficiency of fuzzy matching in R. Regular expressions provide a powerful way to define search patterns and perform complex string matching operations. Algorithms such as the Levenshtein distance algorithm or the Knuth-Morris-Pratt algorithm can be used to efficiently find approximate matches based on string similarity or specific patterns within a larger sequence of characters.
In summary, when performing fuzzy matching in R, choosing the appropriate data structures is crucial for efficient and accurate results. By using data structures like tries, edit distance matrices, and algorithms like regular expressions, one can effectively compare strings, find approximate matches, and identify patterns or similarities based on predefined criteria.
Implementing Parallel Processing

When working with fuzzy matching algorithms in R, it is common to encounter scenarios where the amount of data and the complexity of the matching process require efficient computation. One way to improve the performance of fuzzy matching is by implementing parallel processing techniques.
Parallel processing involves dividing a task into smaller subtasks, which are then executed simultaneously on multiple processors or cores. This approach allows for faster computation and can greatly speed up the matching process.
In the context of fuzzy matching, parallel processing can be applied to various steps of the algorithm. For instance, the calculation of fuzzy distances between character sequences or the evaluation of approximate string matching using regular expressions can be parallelized.
By dividing the data and distributing the workload across multiple processors, each processor can handle a subset of the data, reducing the overall processing time. This is especially useful when dealing with large datasets or when performing complex matching operations.
To implement parallel processing in R, there are various packages and functions available that support parallel computation, such as “parallel”, “foreach”, and “doParallel”. These packages provide tools for creating parallel loops, executing code in parallel, and managing parallel resources.
Additionally, when implementing parallel processing, it is important to consider the potential trade-offs. While parallelization can improve performance, it also requires extra resources and may introduce additional complexity. Therefore, it is crucial to assess the specific requirements and constraints of the fuzzy matching task before deciding to implement parallel processing.
In summary, implementing parallel processing techniques can significantly enhance the performance of fuzzy matching algorithms in R. By leveraging the power of multiple processors or cores, it is possible to speed up the computation of fuzzy distances, approximate string comparisons, and other matching operations. However, it is essential to carefully evaluate the benefits and potential trade-offs before implementing parallel processing in order to achieve optimal results.
FAQ about topic “Fuzzy Match in R: A Guide to Efficient Text Matching in R”
What is fuzzy match in R?
Fuzzy match in R refers to a method of approximate string matching that allows for variations in spelling, spacing, or word order. It is used to find similarities between texts that may not be an exact match.

